
WebMCP 这个东西出现的意义,其实就一句话:网站不能再只为人写了。
过去三十年,网页所有的设计——从 DOM 结构到 CSS 动效,到弹窗、登录态、滚动加载——都是给人眼看、给人手点的。但今年开始,越来越多的访问者不是人,是 AI 代理。让 AI 用屏幕截图加 DOM 反推的方式去操作网页,等于让一个看不清字的人来按你家电梯。Google-Agent 上线之后这个矛盾就摆到了桌面上:代理来了,但网站没准备好。
2026 年 2 月,谷歌 Chrome 团队和微软 Edge 团队联合推了一个 W3C 草案,叫 WebMCP(Web Model Context Protocol)。简单说:让网页主动告诉 AI 代理——「我能干什么、参数怎么填、操作完成后页面会怎么变」。这是一个浏览器级别的标准,不是某家公司的私货。我看完技术文档之后觉得,这件事值得每个做 SEO、做 AI 产品、做电商运营的人花半小时搞懂。
它跟 Anthropic 那个 MCP 不是一回事
名字撞车导致很多人以为 WebMCP 是 Anthropic MCP 的浏览器版,其实不是。这两个东西分别管前端和后端。
Anthropic MCP 是后端协议。它定义的是:Claude、ChatGPT 这种大模型平台,怎么连接你公司的服务器、数据库、代码仓库。你需要部署一个独立的 MCP 服务器进程,配 API Key 和 OAuth,跨网络通信。它的典型用法是「让 Claude 能查我们公司内网 Confluence」「让 ChatGPT 能跑 GitHub Action」,跟用户当前看的页面没关系。
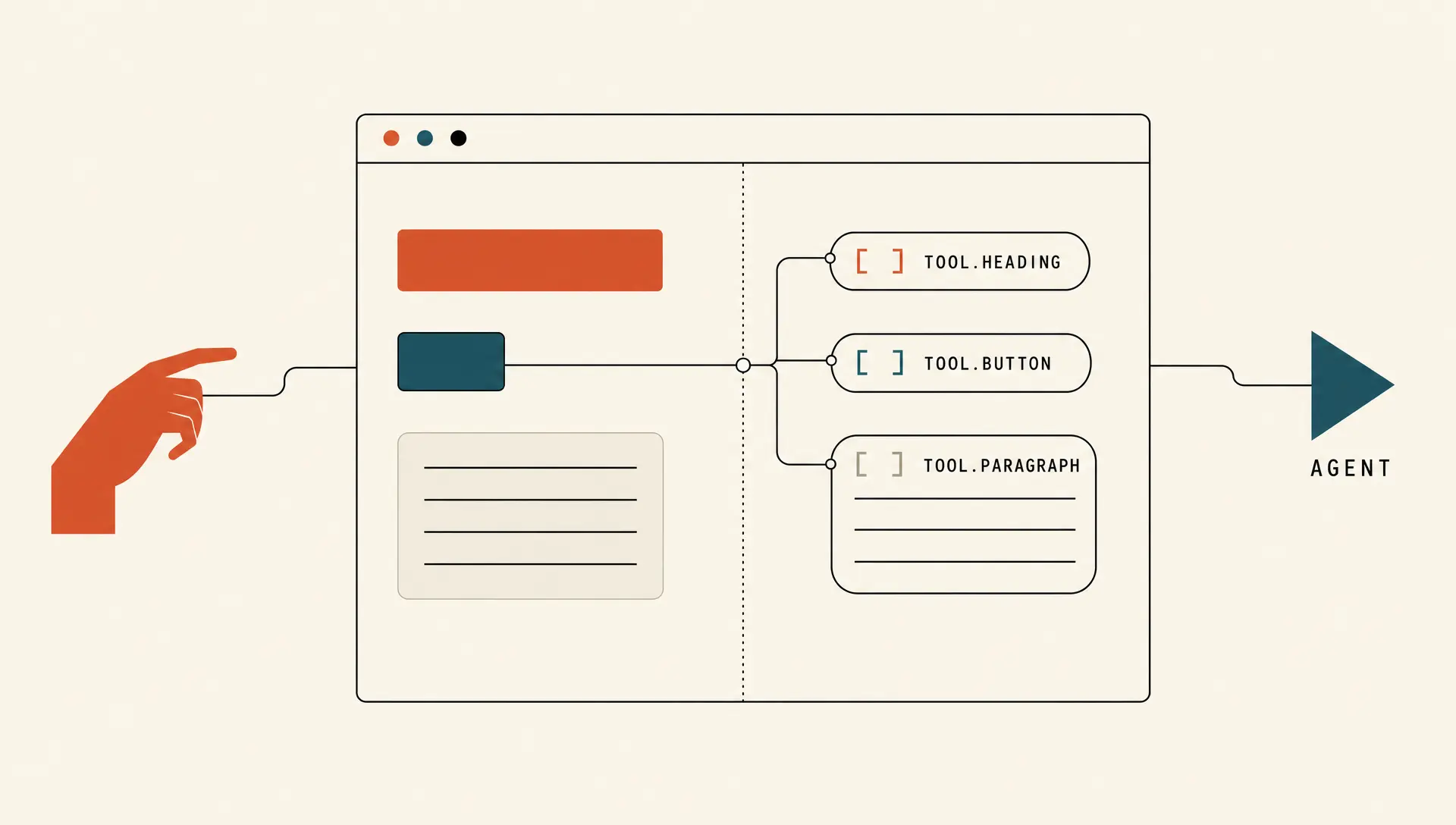
WebMCP 是浏览器原生协议。没有独立服务器。你正在浏览器里加载的这个网页,本身就是临时的「MCP 服务器」。代理通过 window.navigator.modelContext 直接调你前端注册的工具函数,跟你点表单按钮调的是同一套 JavaScript 逻辑。它复用浏览器里已有的 Cookie 和 Session,所以不用再单独搞一套认证。
一个面向后端,一个面向前端;一个为模型理解数据,一个为代理操作页面。一个成熟的 AI 产品架构应该是两个一起用,不是二选一。
实操层面,开发者要做什么
WebMCP 给了两套 API,按工作量从轻到重排:
声明式 API:在 HTML 表单上加两个属性就完事。
<form toolname="bookFlight" tooldescription="搜索并预订往返机票">
<input name="from" toolparamdescription="出发城市,IATA 三字码">
<input name="to" toolparamdescription="到达城市,IATA 三字码">
</form>就这么简单。浏览器引擎会自动把这个表单序列化成 JSON Schema,提供给 AI 代理。代理看到的不是「页面上有个红色 div」,而是「这里有个 bookFlight 工具,需要 from 和 to 两个 IATA 字段」。零 JavaScript 基础的静态页面也能接入。
有个细节挺关键:toolautosubmit 属性。带上它,代理填完字段会自动提交;不带,代理只能填字段,最终的提交按钮必须人来点。这等于在协议层就内置了 human-in-the-loop。给金融、医疗、政务类页面留了一道保险。
命令式 API:复杂前端用这个。SPA、状态机驱动的应用、Canvas 类网页,光提交表单不够,需要在 JS 运行时动态注册工具:
navigator.modelContext.registerTool({
name: "addToCart",
description: "把指定 SKU 加入购物车",
inputSchema: { /* JSON Schema */ },
execute: async (params) => {
// 直接复用现有的前端业务逻辑
await store.addItem(params.sku, params.quantity);
return { success: true };
}
});注意 execute 是在浏览器主线程里跑的,跟你平时用 React/Vue 写的逻辑没区别。这意味着代理调用的同时,用户能看着页面上的购物车数字动起来——这是它跟「直接调 REST API」最大的区别,后面会展开。
「为什么不直接走 REST API?」——这是被吵得最凶的问题
WebMCP 的草案在 Hacker News 上炸出一片质疑:「我们花了十年解耦前后端,现在搞个 Headless 架构 AI 直接调 API 多干净,凭什么又绕回浏览器?」
这个问题我自己也想了好几天,最后觉得 WebMCP 的存在是有道理的,至少有三个 REST API 解决不了的问题:
第一,发现机制。每家公司的 REST API 都是异构的:分页规则不一样、错误码不一样、认证方式不一样。让 AI 代理代用户在 50 个电商网站比价加购,意味着要硬编码 50 套 API 适配器,没人干得起。WebMCP 在前端层给了统一的发现机制——代理打开网页就能问「你能干什么」,不用读文档。这点跟 llms.txt 是一个思路,标准化才能规模化。
第二,共享上下文。这是后端工程师最容易忽略的。如果 AI 代理静默调 API 完成了下单,用户盯着网页根本不知道发生了什么,购物车没变、订单状态没刷,直到收到扣款短信才反应过来。WebMCP 因为执行在前端主线程,操作完成后页面会立刻同步——用户能看着字段被一个一个填好,看着购物车角标跳数字。这种「我看着 AI 在帮我操作」的可视化协同,是建立信任的基础。
第三,认证一致性。走 REST API 路线,AI 代理得拿到你的 API Key 或 OAuth Token,这个授权链条又长又危险。WebMCP 直接复用你浏览器当前的登录态——你能访问的页面,代理就能在同样权限范围内操作。安全边界跟用户自己点击是完全一致的。
所以 WebMCP 不是 REST API 的替代,而是消费端代理操作场景的补充。后端跟后端对接走 MCP / REST,用户屏幕上的代理操作走 WebMCP。
蜜罐:一个意料之外的用法
规范出来不到一周,Hacker News 上有人提了个反向用法,我看完笑出声。
WebMCP 既然是给 AI 代理用的,那网站可以故意注册一个「蜜罐工具」——比如叫 signUpForFreeDemo,描述写得特别诱人。真人用户根本看不到这个工具,他们只会点页面上的真按钮。但那些到处扫接口、试漏洞的恶意爬虫和滥用机器人,会贪婪地枚举所有暴露的工具调用一遍。
后端只要发现有请求是从这个蜜罐工具进来的,可以 100% 判定不是人,直接封 IP。这是协议本身带来的「副作用」——但确实给反作弊做了一件趁手的工具。这种事的乐趣就在这儿,规范设计的人没想到的用法,社区两天就挖出来了。
对 SEO 和品牌端的真实影响
开发者层面以外,更值得做营销和增长的人想清楚的,是流量分发逻辑的变化。
整个 Web 现在正在长出一个三层的「AI 发现协议栈」:
-
治理层:
robots.txt。决定哪些 AI 爬虫能进。 -
理解层:llms.txt。给 AI 一份精简 Markdown 概要,让它快速读懂你。
-
操作层:WebMCP。让 AI 代理能在你网站上完成具体动作。
前两层解决「被看见」「被理解」的问题,WebMCP 第一次直接解决了「被使用」的问题。这三层缺一个,AI 时代的可达性都会折扣。
顺着这个逻辑往前推,会发生什么?
用户对着 Claude 说「帮我订下周去新加坡最便宜的两班机票,能退签」。代理在后台同时打开 5 个航司网站。A 航司还在用 2018 年那套混淆代码堆砌的 React 单页,AI 半天找不到下单按钮;B 航司接入了 WebMCP,前端暴露了 searchFlights 和 bookTicket 两个工具,参数清晰、结果可验证。
结果毫无悬念:订单被导给 B 航司。A 航司不是输给了价格,是输给了「机器可读性」。
这就是为什么我说 WebMCP 是代理引擎优化(AEO)和 GEO 的下一站。AI Overviews 改的是搜索结果摘要,零点击搜索抢的是流量,但 WebMCP 抢的是转化动作本身。前面那些是被 AI「替你回答了」,WebMCP 是被 AI「替你下单了」。
实战观察:我们最近接触的两个跨境电商客户,已经开始问我们「能不能让 ChatGPT 直接在我们站上完成购物」。这个问题去年根本没人提。它不是技术好奇心,是真实的业务焦虑——他们看到 Agentic Commerce 在欧美的渗透速度,知道再不动手,下一波订单流就跟自己没关系了。
现在该做什么
WebMCP 还在 W3C 草案阶段,原生支持目前只在 Chrome 146 Canary 的实验功能里。但有一个开源项目叫 MCP-B,提供了 polyfill 加浏览器扩展的桥接方案——你今天就可以在 Vue/React 项目里引入 @mcp-b/webmcp-polyfill,按标准 API 写代码。等浏览器原生支持落地,把 npm 包卸载就完事,业务代码一行不用改。
这种「面向标准而不是面向当下实现」写代码的方式,是这次最值得做的投入。判断标准也很简单:
如果你的网站核心动作是表单类(注册、预约、下单、提交工单):声明式 API 就够。挑 1-2 个最高频的表单加上 toolname 和 tooldescription,半天能干完,先跑通链路。
如果你的产品是 SPA、Dashboard、复杂状态应用:用命令式 API 注册 3-5 个核心工具——筛选、搜索、添加到清单、导出——这些代理调用频次最高的动作。配合 Schema Markup 和 SSR,前后端 AI 可见性都补齐。
如果你是品牌方 / 营销负责人:这件事得列进明年规划。问技术团队两个问题:第一,我们的核心转化路径,AI 代理能不能完整跑通?第二,我们什么时候能把这些路径用 WebMCP 暴露出去?答不上来,就该开会了。
最后说一句
响应式设计当年也是「噢这又是个新玩具」的态度被忽视了两年,等大家反应过来手机流量超过 PC,没接的网站全得返工重做。WebMCP 的窗口期我估计也就 18-24 个月。前面那一波接入的,会在 AI 代理时代抢到先发优势;后面追赶的,得花两倍力气才能补回来。
SEO 的本质从来没变过——让搜索引擎更容易理解和使用你的内容。只是搜索引擎从「网页索引」变成了「答案引擎」,现在又在变成「执行代理」。每一次范式切换,都有一批网站因为没跟上而消失,也有一批因为跟得快而起飞。WebMCP 是这一轮的入场券。
翼果洞察:从 robots.txt 到 llms.txt 到 WebMCP,互联网正在长出一套新的「机器接口层」。它跟人能看到的视觉层并行存在,但决定的是 AI 代理能不能找到你、读懂你、用上你。眼下投入这一层的成本不高,红利窗口却很短。
关于作者
Linus 这两年带客户跑过 AI Overviews 上线后的流量复盘、做过多轮 GEO 内容改造,也帮跨境电商客户拆过他们「被 ChatGPT 推荐」和「被 ChatGPT 跳过」之间的差距。WebMCP、Agentic Commerce 这一类协议级的东西,他会一边盯草案演进,一边在客户项目里小步试。
这篇文章里的判断,来自他读 W3C 规范、跟前端工程师对接 MCP-B 实施、以及跟客户一起想清楚「下一波订单流到底在哪里」时积累的观察。